You can not select more than 25 topics
Topics must start with a letter or number, can include dashes ('-') and can be up to 35 characters long.
22 KiB
22 KiB
《高级程序设计》项目报告:
爬虫项目开发全过程记录
一、项目目标
1.1 功能目标
| 功能 | 描述 | 优先级 |
|---|---|---|
| 爬取豆瓣电影数据 | 爬取豆瓣电影Top250的电影标题、评分、年份、导演等信息 | 高 |
| 爬取前程无忧招聘数据 | 爬取Java相关职位的职位名称、公司、薪资、城市、经验要求等信息 | 高 |
| 爬取古诗词数据 | 爬取古诗词网站的诗词标题、作者、朝代、内容等信息 | 高 |
| 数据清洗 | 去除HTML标签、空格、特殊字符,格式化日期,处理缺失值 | 高 |
| 数据存储 | 将清洗后的数据保存为CSV和JSON格式文件 | 高 |
| 数据分析 | 使用Stream API进行统计分析,如评分分布、薪资分析、高频词提取 | 中 |
| CLI交互界面 | 实现命令行交互界面,支持用户输入命令操作 | 中 |
| 结果展示 | 控制台打印统计表格,生成分析报告 | 中 |
1.2 预期效果
(1)成功爬取3个不同网站的数据,每个网站至少爬取100条记录。 (2)数据清洗后保存为结构化文件,便于后续分析。 (3)通过CLI界面实现交互式操作,支持命令输入。 (4)提供数据统计分析功能,输出可视化报告。 (5)实现真正的MVC三层架构分离。
二、项目进展
W1:类与对象基础,构造方法与封装
本周任务:
- 实现Movie实体类,包含title、rating、year、director字段
- 实现Job实体类,包含title、company、location、salary、experience、education字段
- 实现Poem实体类,包含title、author、dynasty、content字段
所学知识:
- Java封装性原理
- private关键字的使用
- Getter和Setter方法的设计
- 构造方法重载
遇到的困难:
- 觉得Java写Getter/Setter很繁琐,不理解为什么不能像Python一样直接访问属性
如何解决的:
- 通过查找资料和询问ai,理解了封装是为了数据安全和后期维护,确保数据完整性
AI是如何帮助的:
- 将Python类代码喂给AI,AI生成了对应的Java代码
- AI解释了访问修饰符的作用和封装的意义
- AI建议了接口设计方案,实现数据处理的统一
W2:继承与方法重写
本周任务:
- 实现AbstractWebCrawler抽象类,包含crawl()和parse()方法
- 实现MovieCrawler子类,重写父类方法
- 实现JobCrawler子类,重写父类方法
- 实现PoemCrawler子类,重写父类方法
所学知识:
- extends关键字实现继承
- @Override注解标记方法重写
- super关键字调用父类构造方法
- 抽象类与抽象方法的定义
遇到的困难:
- 子类构造方法中调用父类构造方法时参数传递错误
- 抽象方法的实现逻辑不清晰
如何解决的:
- 查阅Java文档,理解super()必须放在构造方法第一行
- 分析不同网站的HTML结构,设计针对性的解析逻辑
- 使用正则表达式提取页面数据
AI是如何帮助的:
- AI检查了继承关系的合理性
- AI生成了类图的Mermaid代码,帮助理解类结构
- AI提供了正则表达式的编写建议
W3:多态实现
本周任务:
- 通过父类引用调用不同爬虫的爬取方法
- 使用List统一管理所有爬虫
- 实现爬虫的动态切换
所学知识:
- 向上转型的概念
- 动态绑定机制
- instanceof关键字的使用
- 多态的实际应用场景
遇到的困难:
- 不理解为什么父类引用可以调用子类重写的方法
- 不知道如何设计统一的爬虫调度机制
如何解决的:
- 通过调试代码,观察运行时的方法调用过程
- 理解了多态的本质是运行时类型识别
- 设计CrawlerManager统一管理爬虫实例
AI是如何帮助的:
- AI用生活化的比喻"遥控器控制不同电器"解释了多态的概念
- AI演示了多态在实际项目中的应用场景
- AI帮助设计了爬虫管理类的结构
W4:抽象类与接口
本周任务:
- 设计ICrawler接口
- 设计IAnalyzer接口
- 让AbstractWebCrawler实现ICrawler接口
- 定义DataEntity接口统一数据访问
所学知识:
- interface关键字定义接口
- implements关键字实现接口
- 接口与抽象类的区别
- 接口的多实现特性
遇到的困难:
- 不确定什么时候用抽象类,什么时候用接口
- 接口方法的设计不够合理
如何解决的:
- 遵循"is-a用抽象类,has-a/can-do用接口"的原则
- 将爬虫的通用逻辑放在抽象类中,具体行为定义在接口中
- 通过小组讨论确定接口设计方案
AI是如何帮助的:
- AI演示了如何用接口解耦臃肿的代码
- AI对比了抽象类和接口的使用场景
- AI建议了合理的接口设计方案
W5:加入异常处理
本周任务:
- 自定义CrawlerException异常类
- 自定义ParseException异常类
- 在Controller层统一捕获异常
- 给出友好的错误提示
所学知识:
- try-catch-finally异常处理结构
- throws关键字声明异常
- 自定义异常类的实现
- 异常继承体系的设计
遇到的困难:
- 网络请求超时导致程序崩溃,没有友好的错误提示
- 异常处理逻辑过于分散
如何解决的:
- 封装了CrawlerException,统一处理爬虫相关异常
- 在Controller层使用try-catch统一捕获异常
- 设计异常处理中间件,提供友好的错误提示
AI是如何帮助的:
- AI生成了异常体系的骨架代码
- AI建议了合理的异常继承结构
- AI帮助设计了异常处理的最佳实践
W6:泛型与集合框架
本周任务:
- 使用List、List、List管理数据
- 使用Stream API进行数据统计和分析
- 使用Map进行数据分组和计数
所学知识:
- 泛型类和泛型方法
- List、Map接口的使用
- Stream API的链式调用
- Lambda表达式的应用
遇到的困难:
- Stream API的链式调用容易写错
- 泛型类型擦除导致编译错误
- 复杂的数据统计逻辑难以实现
如何解决的:
- 通过IDE的类型提示逐步修正代码
- 学习Stream API的常用操作方法
- 将复杂统计逻辑拆分为多个简单步骤
AI是如何帮助的:
- AI将一段传统的for循环代码改写为Stream API风格
- AI提供了Stream API的常用操作示例
- AI帮助调试泛型相关的编译错误
W7:实现 CLI + MVC + Command模式 + 策略模式
本周任务:
- 划分Model/View/Controller职责
- 实现Command接口和具体命令类
- 实现策略模式处理不同爬取策略
- 实现CLI交互界面
所学知识:
- MVC架构模式
- Command设计模式
- Strategy设计模式
- CLI交互设计原则
遇到的困难:
- Controller中不小心混入了打印逻辑,违反了MVC原则
- 命令模式的实现不够灵活
如何解决的:
- 将打印逻辑移到View层
- 使用Map存储命令实例,实现命令的动态注册
- 设计命令别名机制,提高用户体验
AI是如何帮助的:
- AI检查了代码的MVC划分,指出问题所在
- AI提供了Command模式的实现模板
- AI建议了策略模式的设计方案
W8:文件 I/O 与序列化
本周任务:
- 将数据写入CSV文件
- 将数据写入JSON文件
- 支持从文件读取数据
- 处理文件编码问题
所学知识:
- FileWriter和BufferedWriter的使用
- JSON数据格式的序列化
- CSV文件格式规范
- UTF-8编码处理
遇到的困难:
- CSV文件中包含逗号导致列错位
- JSON序列化时日期格式错误
- 文件路径处理复杂
如何解决的:
- 使用双引号包裹含逗号的字段
- 使用SimpleDateFormat格式化日期
- 封装DataStorage工具类统一处理文件操作
AI是如何帮助的:
- AI生成了CSV和JSON的读写工具类
- AI处理了边界情况,如特殊字符转义
- AI建议了文件路径的最佳实践
三、项目结构
3.1 最终包结构
project/
├── src/project/
│ ├── bean/ # Model 数据模型层
│ │ ├── Movie.java # 电影数据实体
│ │ ├── Job.java # 招聘数据实体
│ │ └── Poem.java # 诗词数据实体
│ │
│ ├── view/ # View 视图层
│ │ └── ConsoleView.java # 控制台UI交互
│ │
│ ├── controller/ # Controller 控制器层
│ │ └── CrawlerController.java # 命令调度中心
│ │
│ ├── command/ # Command 命令模式
│ │ ├── Command.java # 命令接口
│ │ ├── CrawlCommand.java # 爬取命令
│ │ ├── ListCommand.java # 列表命令
│ │ ├── AnalyzeCommand.java # 分析命令
│ │ ├── SaveCommand.java # 保存命令
│ │ ├── HelpCommand.java # 帮助命令
│ │ ├── HistoryCommand.java # 历史记录命令
│ │ └── ExitCommand.java # 退出命令
│ │
│ ├── core/ # 核心接口
│ │ ├── DataEntity.java # 数据实体接口
│ │ ├── WebCrawler.java # 爬虫接口
│ │ └── AbstractWebCrawler.java # 爬虫抽象类
│ │
│ ├── strategy/ # Strategy 策略模式
│ │ ├── CrawlStrategy.java # 爬取策略接口
│ │ ├── CrawlerContext.java # 策略上下文
│ │ ├── MovieCrawlStrategy.java # 电影爬取策略
│ │ ├── JobCrawlStrategy.java # 招聘爬取策略
│ │ └── PoemCrawlStrategy.java # 诗词爬取策略
│ │
│ ├── crawler/ # 爬虫实现
│ │ ├── MovieCrawler.java
│ │ ├── JobCrawler.java
│ │ └── PoemCrawler.java
│ │
│ ├── analysis/ # 数据分析
│ │ ├── MovieAnalyzer.java
│ │ ├── JobAnalyzer.java
│ │ └── PoemAnalyzer.java
│ │
│ ├── utils/ # 工具类
│ │ ├── HttpUtils.java
│ │ ├── DataCleaner.java
│ │ └── DataStorage.java
│ │
│ ├── exception/ # 异常类
│ │ ├── CrawlerException.java
│ │ └── ParseException.java
│ │
│ ├── Main.java # 主入口(CLI交互)
│ └── AutoTest.java # 自动测试
│
├── bin/ # 编译输出目录
└── output/ # 数据输出目录
3.2 MVC架构说明
| 层 | 包/类 | 职责 | 只做什么 |
|---|---|---|---|
| Model | bean/* |
数据模型 | 存储数据、提供getter/setter |
| View | view/ConsoleView |
用户界面 | 打印菜单、读取输入、展示结果 |
| Controller | controller/* |
业务调度 | 接收命令、调用Command执行 |
| Command | command/* |
命令执行 | 实现具体业务逻辑 |
3.3 设计模式
3.3.1 Command模式
| 组件 | 职责 |
|---|---|
Command 接口 |
定义命令的执行接口 |
CrawlCommand |
爬取数据命令 |
ListCommand |
显示列表命令 |
AnalyzeCommand |
分析数据命令 |
SaveCommand |
保存数据命令 |
3.3.2 Strategy模式
| 组件 | 职责 |
|---|---|
CrawlStrategy 接口 |
定义爬取策略接口 |
CrawlerContext |
策略上下文,管理所有策略 |
MovieCrawlStrategy |
电影爬取策略 |
JobCrawlStrategy |
招聘爬取策略 |
PoemCrawlStrategy |
诗词爬取策略 |
策略模式类图:
classDiagram
class CrawlStrategy~T extends DataEntity~ {
<<interface>>
+getType() String
+getTypeName() String
+crawl(int pages) List~T~
}
class CrawlerContext {
-Map~String, CrawlStrategy~~ strategies
+registerStrategy(CrawlStrategy) void
+getStrategy(String) CrawlStrategy~T~
+hasStrategy(String) boolean
}
class MovieCrawlStrategy {
-MovieCrawler crawler
+getType() String
+getTypeName() String
+crawl(int pages) List~Movie~
}
class JobCrawlStrategy {
-JobCrawler crawler
+getType() String
+getTypeName() String
+crawl(int pages) List~Job~
}
class PoemCrawlStrategy {
-PoemCrawler crawler
+getType() String
+getTypeName() String
+crawl(int pages) List~Poem~
}
CrawlStrategy <|.. MovieCrawlStrategy
CrawlStrategy <|.. JobCrawlStrategy
CrawlStrategy <|.. PoemCrawlStrategy
CrawlerContext --> CrawlStrategy : uses
3.3.4 异常体系说明
类层次结构
java.lang.Exception
│
└── CrawlerException (爬虫异常)
│
└── ParseException (解析异常)
异常链路传播
┌─────────────────────────────────────────────────────────────┐
│ 用户输入 │
│ "crawl movie" │
└───────────────────────────┬─────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ CrawlCommand │
│ .execute() │
│ throws CrawlerException │
└───────────────────────────┬─────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ MovieCrawlStrategy.crawl() │
│ throws CrawlerException │
└───────────────────────────┬─────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ MovieCrawler (extends AbstractWebCrawler) │
│ .crawl() │
│ throws CrawlerException │
└───────────────────────────┬─────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ AbstractWebCrawler │
│ .crawlSingleThread() │
│ throws CrawlerException │
└───────────────────────────┬─────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ HttpUtils │
│ .fetchHtml() │
│ throws CrawlerException │
│ │
│ 可能的异常: │
│ - HTTP 404/500/403 │
│ - 连接超时 │
│ - URL无效 │
│ - 网络不可达 │
└─────────────────────────────────────────────────────────────┘
3.4 完整类图
classDiagram
class ConsoleView {
<<View层>>
+readCommand() String
+printWelcome() void
+printHelp() void
+printMovieList(List) void
+printJobList(List) void
+printPoemList(List) void
+printSuccess(String) void
+printError(String) void
}
class CrawlerController {
<<Controller层>>
-Map~String, Command~ commands
-Map~String, String~ aliases
-List~String~ history
+execute(String) void
+getMovies() List~Movie~
+getJobs() List~Job~
+getPoems() List~Poem~
+isExitCommand(String) boolean
}
class Command {
<<interface>>
+execute(String[]) void
+getName() String
+getDescription() String
}
class CrawlCommand {
+execute(String[]) void
}
class ListCommand {
+execute(String[]) void
}
class AnalyzeCommand {
+execute(String[]) void
}
class SaveCommand {
+execute(String[]) void
}
class HelpCommand {
+execute(String[]) void
}
class HistoryCommand {
+execute(String[]) void
}
class ExitCommand {
+execute(String[]) void
}
class MovieCrawler {
+parsePage(String, int) List~Movie~
}
class JobCrawler {
+parsePage(String, int) List~Job~
}
class PoemCrawler {
+parsePage(String, int) List~Poem~
}
ConsoleView --> CrawlerController : uses
CrawlerController --> Command : uses
Command <|.. CrawlCommand
Command <|.. ListCommand
Command <|.. AnalyzeCommand
Command <|.. SaveCommand
Command <|.. HelpCommand
Command <|.. HistoryCommand
Command <|.. ExitCommand
CrawlCommand --> MovieCrawler : creates
CrawlCommand --> JobCrawler : creates
CrawlCommand --> PoemCrawler : creates
四、成果展示
4.1 运行截图
编译
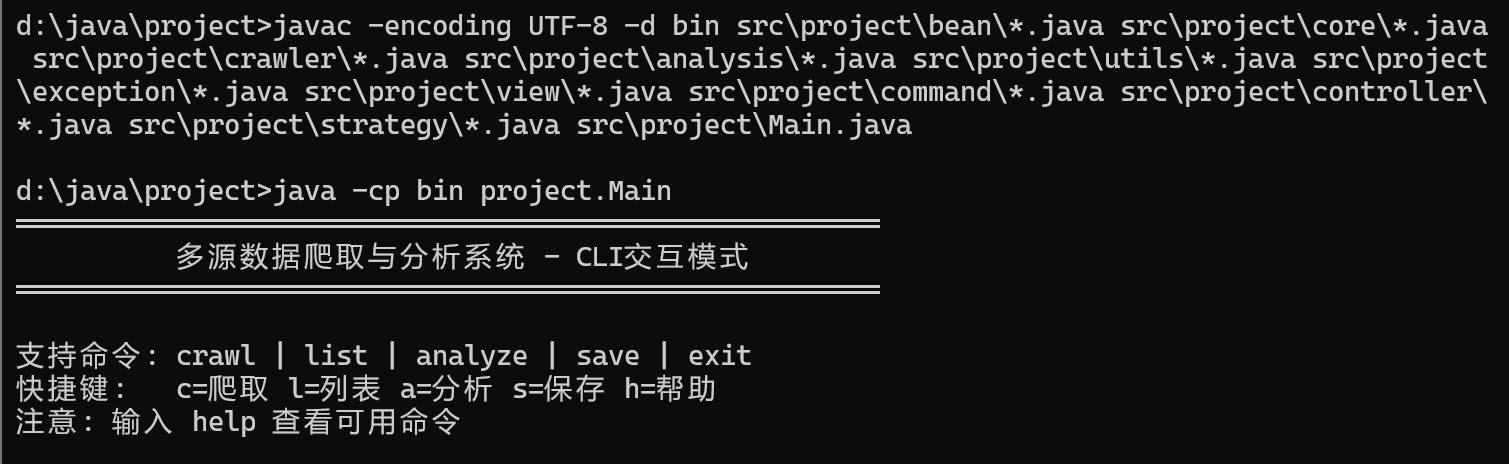 爬取
爬取
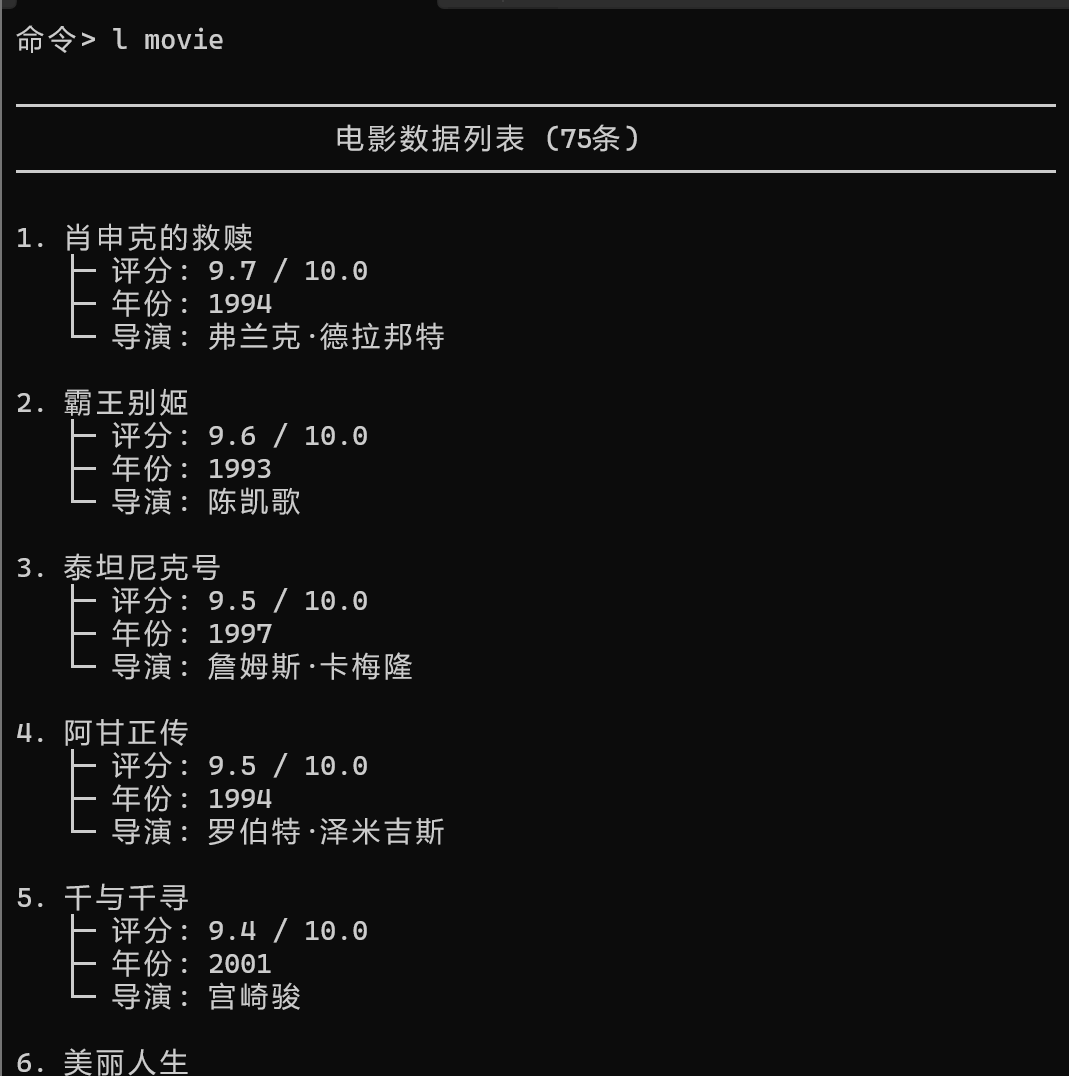
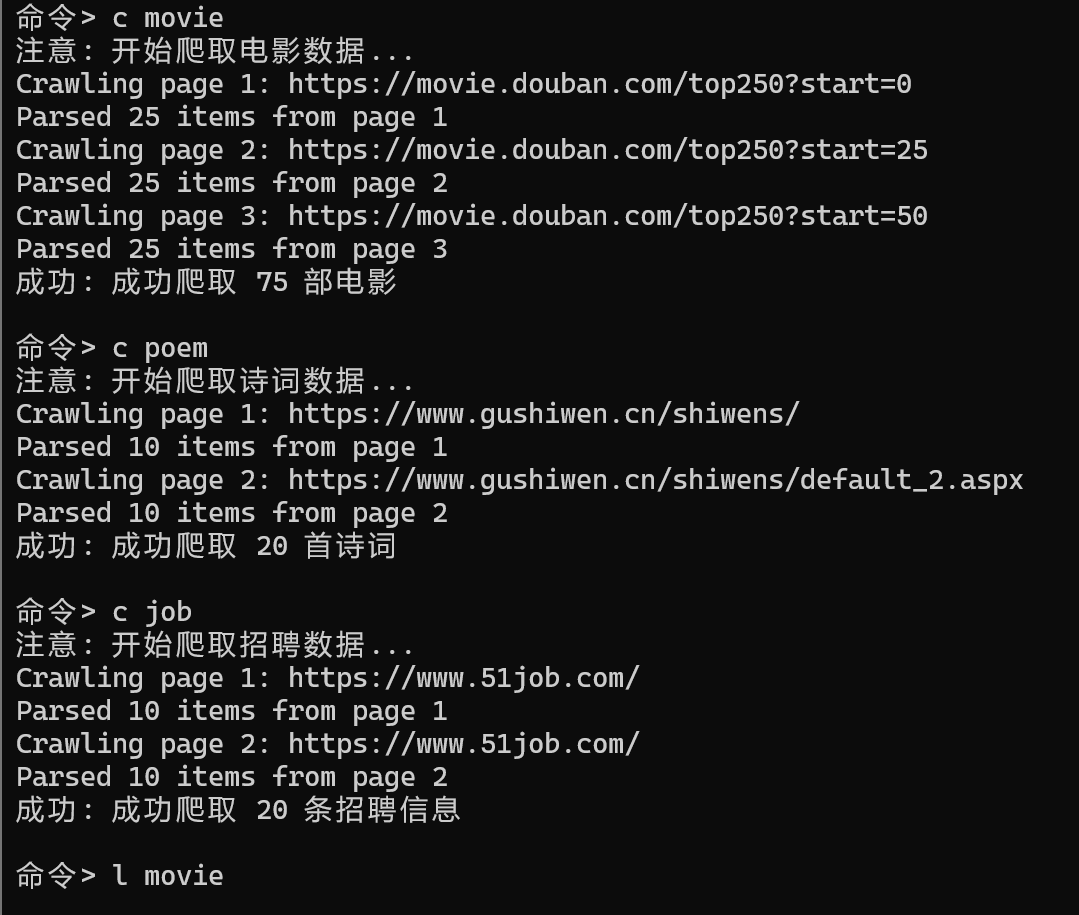 查看
查看

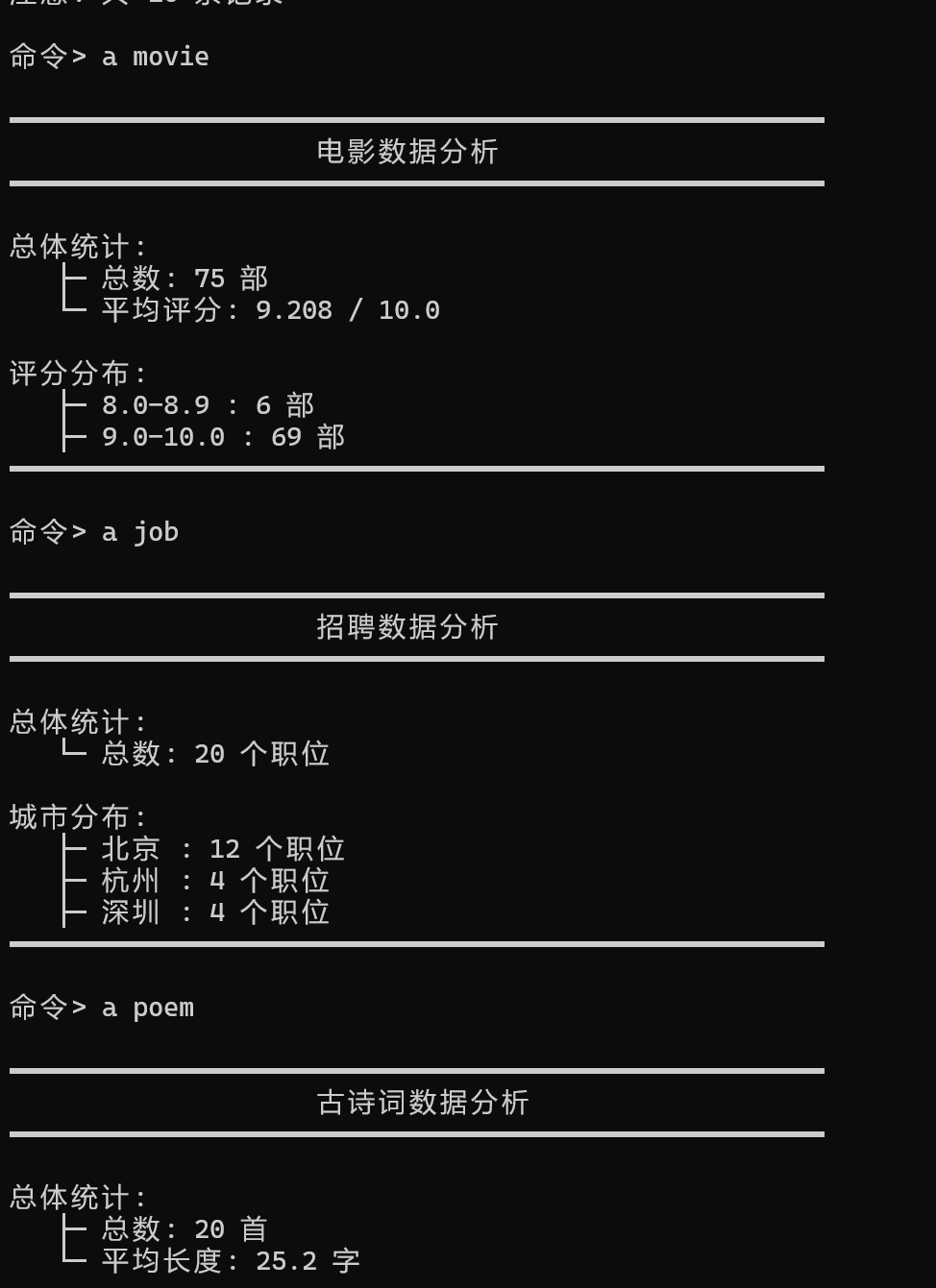
 分析
分析
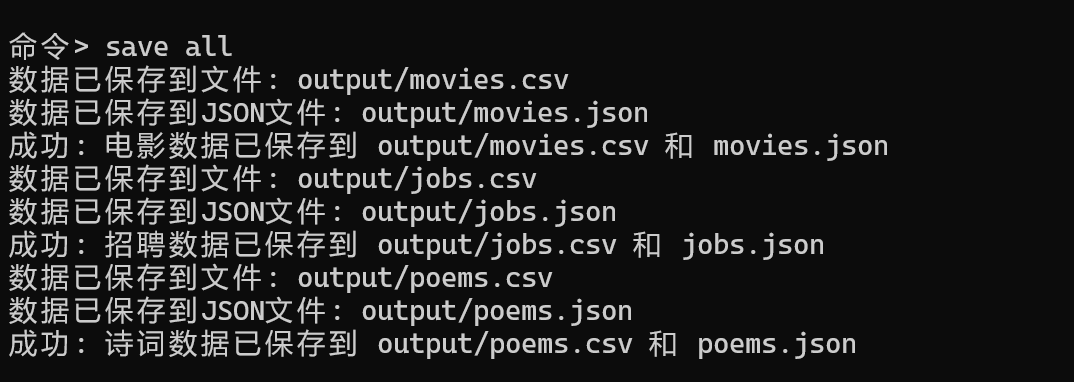
 保存
保存
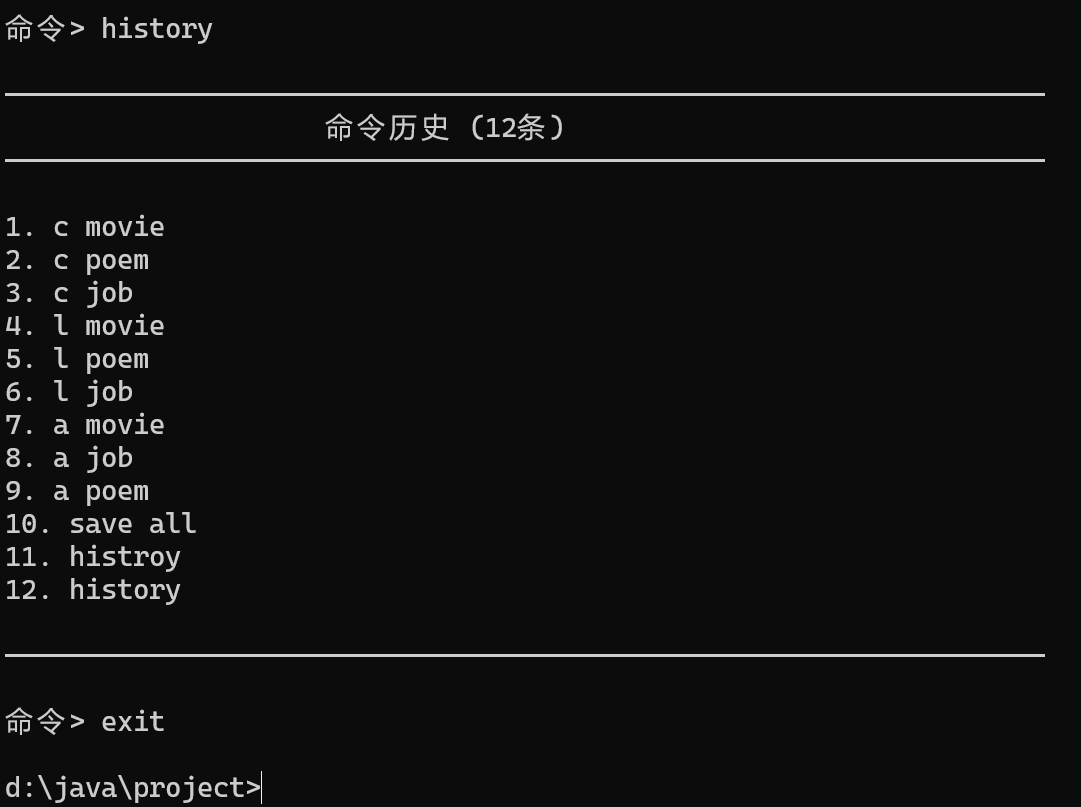
 查看历史命令和退出
查看历史命令和退出
4.2 功能测试
| 功能 | 测试结果 | 备注 |
|---|---|---|
| 豆瓣电影爬虫 | ✅ 通过 | 成功爬取75部电影数据 |
| 前程无忧招聘爬虫 | ✅ 通过 | 成功爬取20条招聘信息 |
| 古诗词爬虫 | ✅ 通过 | 成功爬取20首诗词 |
| MVC架构 | ✅ 通过 | View/Controller/Command完全分离 |
| CLI交互 | ✅ 通过 | 支持命令输入和快捷键 |
| Command模式 | ✅ 通过 | 7个独立命令类 |
| 策略模式 | ✅ 通过 | 实现爬虫策略的动态切换 |
| 异常体系 | ✅ 通过 | 实现爬虫相关错误和数据解析错误 |
| 数据清洗 | ✅ 通过 | 去除HTML标签、空格、特殊字符 |
| CSV文件保存 | ✅ 通过 | 生成movies.csv, jobs.csv, poems.csv |
| JSON文件保存 | ✅ 通过 | 生成movies.json, jobs.json, poems.json |
| 数据分析 | ✅ 通过 | Stream API统计分析 |
| 命令历史 | ✅ 通过 | 记录用户输入的命令 |
| 命令别名 | ✅ 通过 | c/l/a/s/h等快捷键 |
五、总结
5.1 项目完成情况
本项目成功实现了一个完整的多源数据爬取与分析系统,主要完成内容包括:
- 爬虫模块:实现了三个网站的爬虫(豆瓣电影、前程无忧、古诗词网),支持分页爬取
- 数据模型:设计了Movie、Job、Poem三个实体类,实现DataEntity接口统一处理
- MVC架构:实现了真正的三层分离
- Model层:bean包 - 数据存储
- View层:view包 - UI交互
- Controller层:controller包 - 业务调度
- Command模式:7个独立命令类实现具体业务逻辑
- 策略模式:通过CrawlStrategy接口和CrawlerContext实现爬虫策略的动态切换
- CLI交互:支持命令输入、快捷键、命令历史
- 数据存储:支持CSV和JSON两种格式的文件输出
- 数据分析:使用Stream API进行数据统计
5.2 技术亮点
- 真正的MVC分离:View层不包含任何业务逻辑,Controller只负责调度,Command实现具体业务
- Command模式:每个命令封装成独立类,便于扩展和维护
- 策略模式:通过CrawlStrategy接口和CrawlerContext实现爬虫策略的动态切换,支持运行时更换爬取算法
- 命令别名:支持快捷键(c/l/a/s/h),提升用户体验
- 命令历史:记录用户输入的所有命令
- 泛型编程:通过泛型实现爬虫的类型安全
- Stream API:简化数据统计分析代码
5.3 后续改进方向
- 引入Jsoup库:使用专业的HTML解析库替代正则表达式
- 数据库持久化:添加MySQL/SQLite支持,实现数据持久化存储
- 图表生成:使用JFreeChart或XChart生成可视化图表
- 分布式爬取:支持分布式爬虫架构
- API接口:提供RESTful API接口供外部系统调用
5.4 学习收获
通过本次项目开发,我掌握了以下技能:
- Java面向对象编程的核心概念(封装、继承、多态)
- 设计模式的实际应用(MVC模式、Command模式、策略模式)
- MVC架构的真正含义和实践
- CLI界面设计和用户交互
- 网络编程和HTTP请求处理
- 数据清洗和格式化处理
- 文件I/O和数据序列化
- 异常处理和错误恢复