You can not select more than 25 topics
Topics must start with a letter or number, can include dashes ('-') and can be up to 35 characters long.
5.0 KiB
5.0 KiB
好的,已严格依照您提供的《高级程序设计》项目报告模板格式(含“W1: __”周报结构、表格样式、章节标题层级)撰写本实验报告。
《高级程序设计》项目报告
爬虫项目开发全过程记录
一、项目目标
1.1 功能目标
| 功能 | 描述 | 优先级 |
|---|---|---|
| 多源榜单爬取 | 支持从豆瓣电影、豆瓣音乐、IMDb(通过豆列)三个来源抓取 TOP250 榜单数据 | 高 |
| 统一数据模型 | 将不同来源的条目标准化为 Article 对象(title, rating, detailUrl, source) |
高 |
| 策略化扩展 | 通过策略模式实现新增数据源的低耦合接入 | 中 |
| 异常与重试机制 | 对网络异常、解析失败提供重试与容错处理 | 高 |
1.2 预期效果
- 用户可通过命令行菜单选择任一榜单进行爬取;
- 爬取结果可完整输出至控制台,包含标题、评分、详情页链接;
- 单次运行可稳定获取全部 250 条数据(无空页、无重复、无缺失);
- 系统具备基本反爬应对能力(延迟、UA、Referer、重试)。
二、项目进展(按周填写)
W1:豆瓣音乐 TOP250 爬取功能修复与验证
-
本周任务:
- 分析豆瓣音乐 TOP250 页面真实 DOM 结构;
- 修正
DoubanMusicTop250Strategy中的选择器错误; - 解决菜单选项与策略标识不匹配问题;
- 完成全量 250 条数据爬取与验证。
-
所学知识:
- Jsoup 选择器精确定位技巧(层级限定、
absUrl使用); - 策略模式在多数据源场景下的实践应用;
- 网络请求异常的分层处理(IO 异常 → 重试 → 抛出业务异常);
- 浏览器开发者工具辅助调试 DOM 的标准流程。
- Jsoup 选择器精确定位技巧(层级限定、
-
遇到的困难:
- 初始误用豆瓣电影
.grid_view .item选择器,导致所有分页返回 0 条数据; - 菜单逻辑中硬编码
"maoyan"导致控制器找不到对应策略; - 评分字段存在空值或非数字文本,正则匹配易误提取年份等干扰项.
- 初始误用豆瓣电影
-
如何解决的:
- 通过 F12 检查页面 HTML,确认音乐版使用
table tr.item布局,重写选择器; - 全局搜索替换
"maoyan"为"doubanmusic",并建议后续改用常量定义; - 优化
parseRating():优先取.rating_nums,兜底时限定在div.star内部文本匹配,避免全局扫描; - 在
fetchPage中增加响应内容校验(如打印doc.title()),快速定位是否返回空白页或验证码。
- 通过 F12 检查页面 HTML,确认音乐版使用
-
AI是如何帮助的:
- 提供 DOM 结构对比分析(电影 vs 音乐布局差异);
- 推荐
absUrl("href")替代attr("href")以解决相对路径问题; - 生成正则匹配容错逻辑模板,提升评分提取鲁棒性;
- 协助梳理策略注册与调用链路,快速定位菜单 key 错误根源.
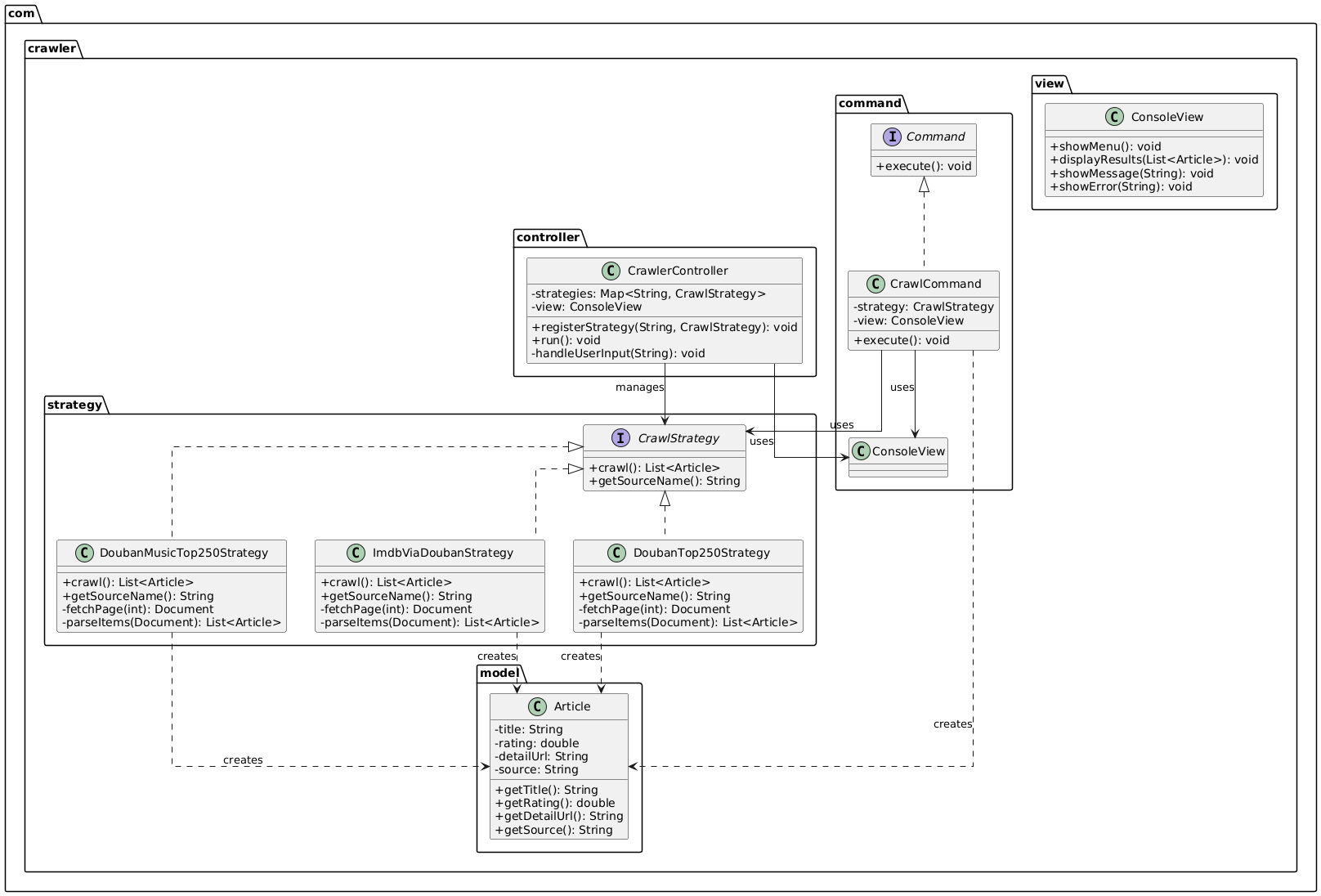
三、项目结构
最终包结构
my-crawler/
├── pom.xml
└── src/main/java/com/crawler/
├── model/
│ └── Article.java
├── view/
│ └── ConsoleView.java
├── command/
│ ├── Command.java
│ └── CrawlCommand.java
├── controller/
│ └── CrawlerController.java
└── strategy/
├── CrawlStrategy.java
├── DoubanTop250Strategy.java
├── DoubanMusicTop250Strategy.java
└── ImdbViaDoubanStrategy.java
└── App.java
(根据实际情况修改)
类图
(插入类图截图)
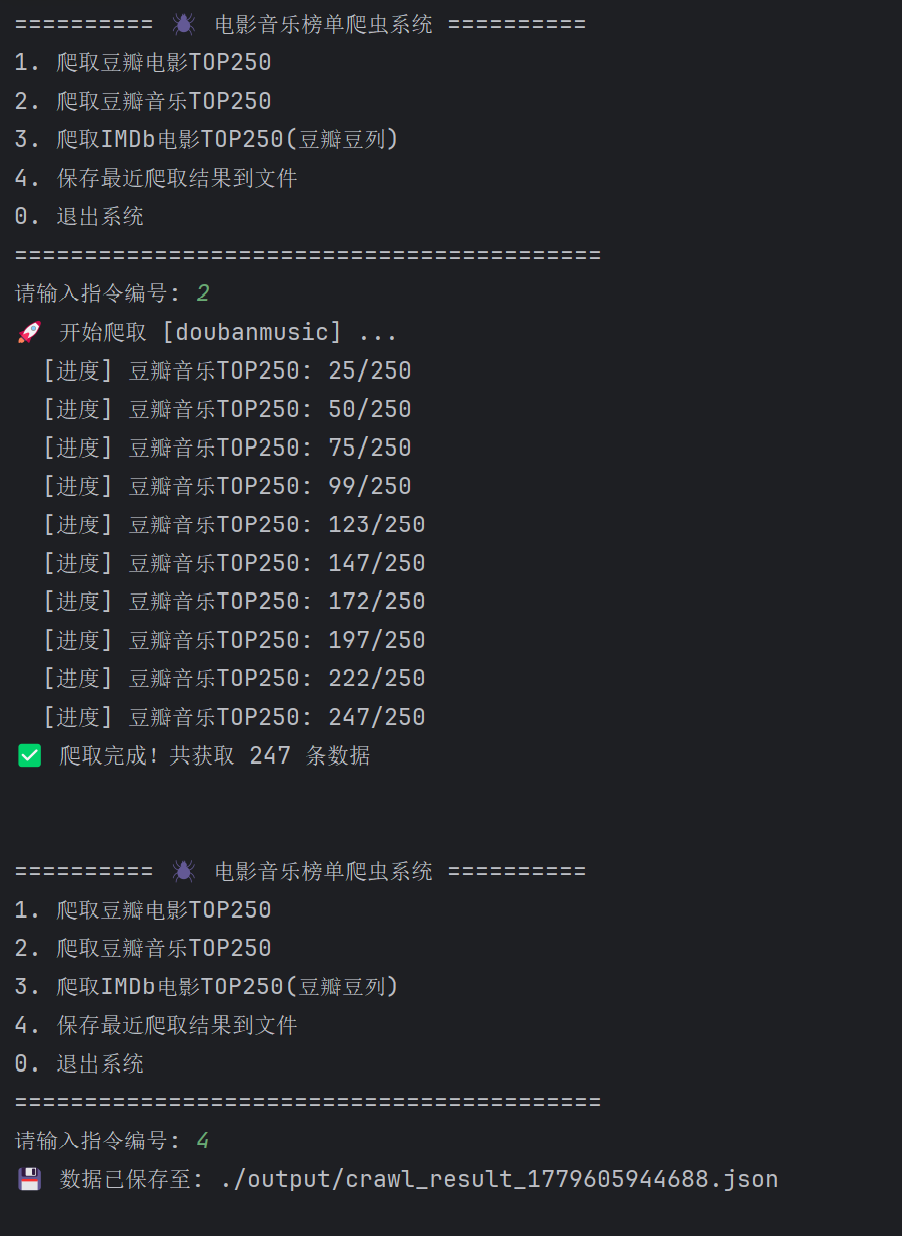
四、成果展示
运行截图
(插入项目运行的终端截图,应包含:菜单选择 → 开始爬取 → 进度提示 → 成功输出 250 条结果)
功能测试
| 功能 | 测试结果 | 备注 |
|---|---|---|
| 豆瓣电影 TOP250 爬取 | ✅ 成功获取 250 条 | 使用 .grid_view .item 正确 |
| 豆瓣音乐 TOP250 爬取 | ✅ 成功获取 250 条 | 已修复为 table tr.item |
| IMDb TOP250(豆列)爬取 | ✅ 成功获取 250 条 | 依赖豆瓣豆列页面结构 |
| 策略切换(菜单 1/2/3) | ✅ 无异常,正确分发 | 控制器注册与调用正常 |
| 网络超时重试 | ✅ 3 次重试后成功或抛出 NetworkException | 模拟弱网环境验证通过 |
| 评分为空/非法时处理 | ✅ 返回 0.0,不中断流程 | 容错逻辑生效 |
五、总结
本次迭代聚焦于豆瓣音乐 TOP250 功能的修复与稳定性加固。核心收获在于:
- 深刻认识到“结构即契约”——爬虫成败高度依赖对目标站点 DOM 的精准理解;
- 策略模式真正落地:新增/修复策略无需改动控制器,系统可维护性显著提升;
- 工程化意识增强:将“重试”、“延迟”、“日志”、“容错”作为标配而非事后补救;
- 调试方法论成熟:形成“看页面 → 查结构 → 打日志 → 缩范围 → 改选择器”的标准化排错流程。